If you are working with data, there are chances that you will come across one of the most popular Python libraries and Pandas. This library is mainly utilized for data analysis and manipulation.
More specifically, iterating through rows in a DataFrame is a common operation in data analysis that can be done using Pandas. It also provides the best methods and practices that make sure the data gets processed efficiently.
So whether you are a beginner or an experienced data analyst, follow this post to get valuable insights that will assist you to work more effectively with your data.
Understanding DataFrames in Pandas
In Pandas, a DataFrame is represented as a table-like structure that comprises multiple columns of different data types. Its structure is similar to a SQL table or a spreadsheet.
More specifically, this data structure is primarily utilized for data analysis and manipulation operations.
Components of DataFrame
Here are the three main components of a DataFrame in Pandas.
- Index – It refers to the index values or the row labels of the DataFrame.
- Columns – Columns are the variable names or column labels of the DataFrame.
- Data – It represents the actual data that is stored in the DataFrame in the form of columns and rows.
How to Create a DataFrame in Python
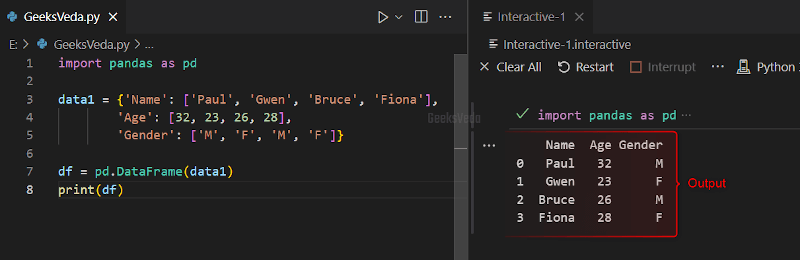
For the purpose of creating a DataFrame in Pandas, first import the Pandas library as pd alias. This library is imported to utilize the Pandas object and the relevant function in the later code.
Next, we created a dictionary called “data1” that stored the information related to the persons, regarding their name, age, and gender. Within the created dictionary, each key signifies a column named and the respective value.
After that, a DataFrame object is created by calling the DataFrame constructor and passing the newly created dictionary as an argument. Lastly, the print() function displayed the DataFrame in a tabular structure.
import pandas as pd
data1 = {'Name': ['Paul', 'Gwen', 'Bruce', 'Fiona'],
'Age': [32, 23, 26, 28],
'Gender': ['M', 'F', 'M', 'F']}
df = pd.DataFrame(data1)
print(df)
It can be observed that the content of the created DataFrame has been displayed on the console.
Different Methods to Iterate Over Rows in Pandas
Let’s enlist the major techniques used to iterate over rows in Python Pandas.
for loopmethoditerrows()methoditertuples()methodapply()method
The below-given subsections will now practically demonstrate the usage of the mentioned approaches.
1. Using for loop Method in Python Panda
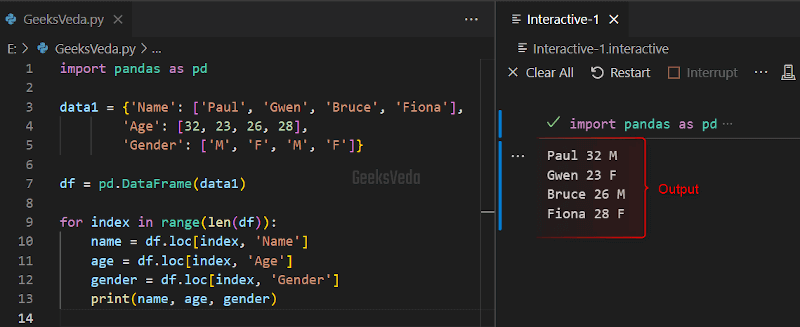
Want to know about the simplest technique related to iterating over rows in Pandas DataFrame? For loop can assist you in this scenario.
By utilizing it, you can loop through each DataFrame row by accessing its index and then resultantly fetching the corresponding column values by using the loc accessor as follows.
mport pandas as pd
data1 = {'Name': ['Paul', 'Gwen', 'Bruce', 'Fiona'],
'Age': [32, 23, 26, 28],
'Gender': ['M', 'F', 'M', 'F']}
df = pd.DataFrame(data1)
for index in range(len(df)):
name = df.loc[index, 'Name']
age = df.loc[index, 'Age']
gender = df.loc[index, 'Gender']
print(name, age, gender)
The for loop can achieve the desired results. However, it may work inefficiently and slowly for large DataFrames having extensive values.
2. Using iterrows() Method in Python Panda
The iterrows() method outputs an iterator that yields pairs of row data and their index, where the row data is referred to as the Pandas series object.
More specifically, this method can be also utilized for iterating over the Pandas DataFrame rows.
To do so, write out the following code to your Python file.
import pandas as pd
data1 = {'Name': ['Paul', 'Gwen', 'Bruce', 'Fiona'],
'Age': [32, 23, 26, 28],
'Gender': ['M', 'F', 'M', 'F']}
df = pd.DataFrame(data1)
for index, row in df.iterrows():
name = row['Name']
age = row['Age']
gender = row['Gender']
print(name, age, gender)
Similar to the previous example, firstly, we have created a dictionary. Then, created a DataFrame out of it.
Then, the for loop iterates through each row of the DatFrame using the index and gets the row values using the iterrows() method, which has been displayed on the console.
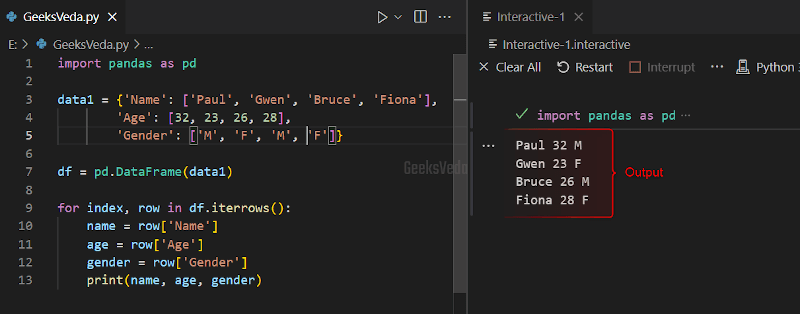
As compared to for loop, this method works faster, however, it still has some performance overhead.
3. Using itertuples() Method in Python Panda
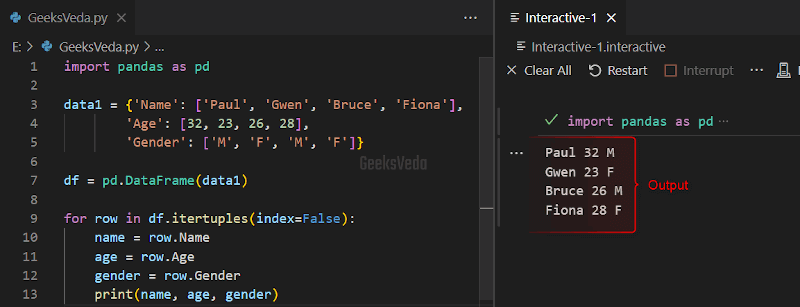
The itertuples() Pandas object method outputs an iterator that yields tuples comprising the row data and the relevant index for each row.
Moreover, it is considered the most efficient and the fastest method to iterate over rows in Pandas, specifically for large DataFrames.
For instance, in the below-provided example, we have utilized the itertuples() method for iterating the rows of the created df DataFrame.
import pandas as pd
data1 = {'Name': ['Paul', 'Gwen', 'Bruce', 'Fiona'],
'Age': [32, 23, 26, 28],
'Gender': ['M', 'F', 'M', 'F']}
df = pd.DataFrame(data1)
for row in df.itertuples(index=False):
name = row.Name
age = row.Age
gender = row.Gender
print(name, age, gender)
4. Using apply() Method in Python Panda
Pandas also offers a versatile method for iterating over the rows in DataFrame, known as apply(). This method enables the required operation on each row by utilizing a custom function.
However, this function may work slower than all of the other discussed approaches, but it is helpful in the use cases where it is needed to perform complex operations.
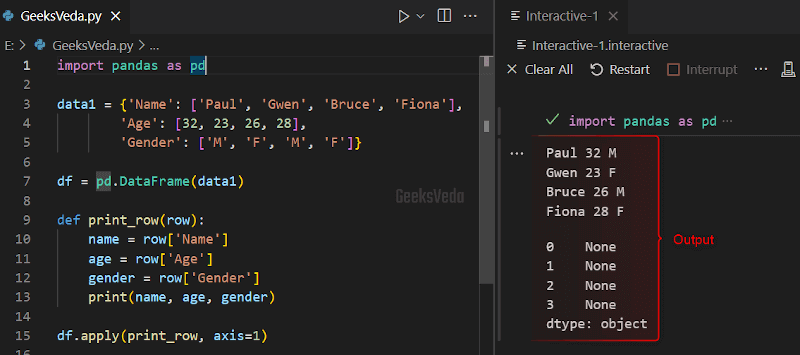
For instance, here in the provided code block, the apply() method is invoked for applying the print_row() function to each DataFrame “df” row
Its “axis-1” argument tells the apply() method to implement this function in each row.
The print_row() function will work in such a way that it takes a row as an input and then retrieves the values of its respective Name, Age, and Gender column values and prints them to the console.
import pandas as pd
data1 = {'Name': ['Paul', 'Gwen', 'Bruce', 'Fiona'],
'Age': [32, 23, 26, 28],
'Gender': ['M', 'F', 'M', 'F']}
df = pd.DataFrame(data1)
def print_row(row):
name = row['Name']
age = row['Age']
gender = row['Gender']
print(name, age, gender)
df.apply(print_row, axis=1)
In the following output, you can see the printed values for each row. The following series of “None” values have been displayed by the print_row() function indicating that the function is not returning anything.
Best Practices to Iterate Over Rows in Pandas
Check out the provided best practices for iterating over the rows in Pandas.
- To perform row-wise operations, utilize the built-in Pandas methods, such as
itertuples(),iterrows(), or vectorized operations likeapply(). - Loops are idealized for those scenarios where it is required to iterate over columns instead of rows for better performance.
- Consider using parallel processing or chunking techniques while iterating over a large DataFrame to improve performance.
- While iterating over a DataFrame in place, avoid modifying it as it can lead to unexpected behavior.
- Loops are analyzed as slow and inefficient as compared to other methods, so avoid using loops whenever possible.
- Avoid creating unnecessary copies of data and specify the most suitable data type for the columns for missing memory usage.
That’s all essential information regarding iterating over rows in Pandas.
Conclusion
Understanding the method for iterating over rows in Pandas DataFrame is an essential skill for any data scientist or analyst. In today’s post, we discussed DataFrame, and its basic structure, and explored different approaches for overeating over rows: for loops, iterrows, itertuples(), and apply() method.
Moreover, we have provided the best practices so that you can carry out the iteration operation more efficiently and effectively. By following our post, you can easily perform the row-wise iterations on the DataFrame and check out the valuable insights from the DataFrame.
Want to explore and learn more related to Python, do check out our dedicated Python Tutorial Series!