Welcome to our today’s guide related to Python regex. In this guide, we will discuss what are regular expressions in Python and how to use the “re” module.
Moreover, we will also explore advanced techniques, such as optimization techniques of the regular expression, lookahead assertions, and how regex can be utilized to improve data validation, streamline text parsing, and perform web scraping.
Let’s start the journey to learn the Python regex dynamic tool!
1. What are Regular Expressions in Python
Regex or Regular expressions are robust sequences of characters that can be utilized for defining search patterns within the text data. These expressions serve as versatile tools for pattern matching and manipulation.
Additionally, it enables you to efficiently extract, replace, and validate strings according to the specified criteria.
Python’s re Module
Python “re” module stands as a powerful toolbox for working with regexes. It offers functions such as “re.match()“, “re.findall()“, and “re.search()” for performing pattern-based operations on strings.
More specifically, the “re.sub()” method enables you to replace matched patterns with the required content.
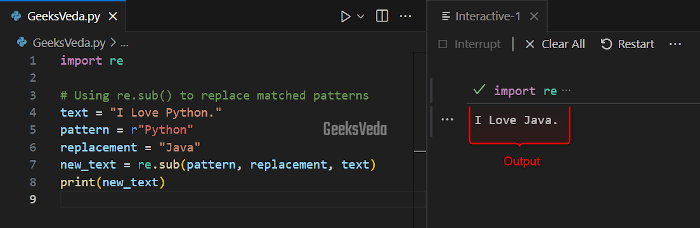
For instance, in the below program, we have invoked the “re.sub()” method for replacing the pattern “Python” with “
import re # Using re.sub() to replace matched patterns text = "I Love Python." pattern = r"Python" replacement = "Java" new_text = re.sub(pattern, replacement, text) print(new_text)
Essential Regex Concepts
Let’s discuss some essential regex concepts in Python such as basic patterns and metacharacters, characters classes, and quantifiers.
1. Basic Meta Characters in Python Regex
Python regex is based on basic patterns and metacharacters that enable precise pattern matching. For instance:
- “
.” dot metacharacters match any characters except a newline. - “
^” caret and “$” dollar sign anchor patterns to the start and the end of the line.
These patterns and metacharacters provide fine control over the matches.
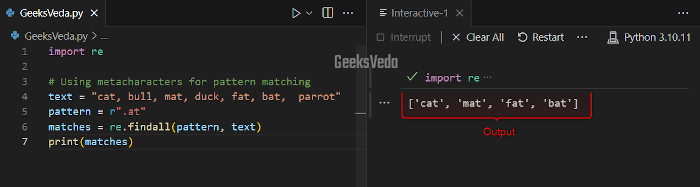
According to the given code, the “.” metacharacter has been added for matching any character that matches with the “at” pattern.
import re # Using metacharacters for pattern matching text = "cat, bull, mat, duck, fat, bat, parrot" pattern = r".at" matches = re.findall(pattern, text) print(matches)
2. Character Classes and Quantifiers
Character classes and quantifiers improve the flexibility of the regular expression. For example, the character classes that are specified within the square brackets “[…]” allows you to match a specified set of characters.
Quantifiers such as “+“‘, “*“, and “?" control the repetition of groups or characters. This consequently permits you to match varying occurrences.
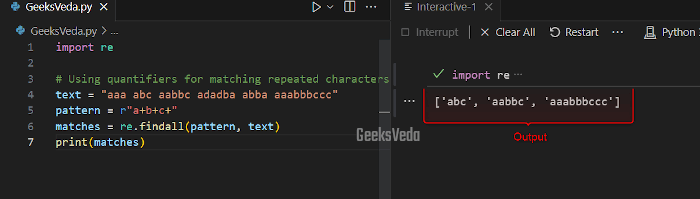
Here, we have added the quantifier “+” within the pattern “a+b+c” that matches the sequences of the repeated “a“, “b“, and “c” characters in the given text.
import re # Using quantifiers for matching repeated characters text = "aaa abc aabbc adadba abba aaabbbccc" pattern = r"a+b+c+" matches = re.findall(pattern, text) print(matches)
Practical Implementation of Python Regex
In Python, the regular expression or regex can be used for matching and searching for particular patterns, extracting valuable data using groups, or replacing and modifying text.
1. Match and Search Technique Using Regex
To locate patterns within the text, matching and searching techniques can be applied using regex. For this scenario, the “re.match()” and “re.search()” functions are used.
More specifically, the “re.match()” method verifies if the pattern matches at the beginning of the string. On the other hand, “re.search()” scans the whole string.
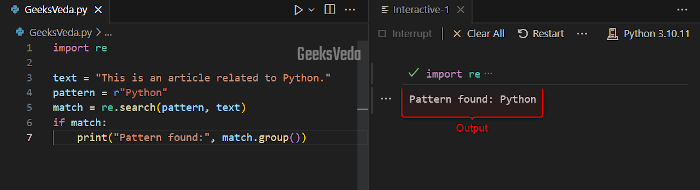
In the following program, we have invoked the “re.search()” method for finding the occurrence of the “Python” pattern in the given text. In case, if the pattern is found, it will display the matched text.
import re
text = "This is an article related to Python."
pattern = r"Python"
match = re.search(pattern, text)
if match:
print("Pattern found:", match.group())
2. Extract Data Using Groups
You can also create groups that isolate specific information. It can be done by enclosing patterns in parentheses. This approach can be found useful when you have to deal with structured data like emails, dates, or phone numbers.
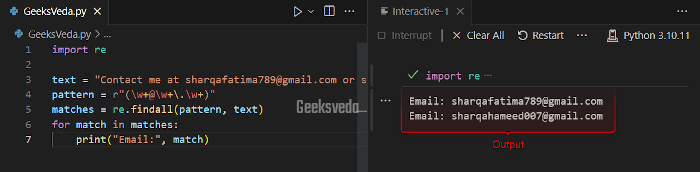
Here, we have added a regex pattern that will extract the email addresses from the given text. This pattern “(\w+@\w+\.\w+)” will capture the valid email formats.
import re
text = "Contact me at sharqafatima789@gmail.com or sharqahameed007@gmail.com."
pattern = r"(\w+@\w+\.\w+)"
matches = re.findall(pattern, text)
for match in matches:
print("Email:", match)
3. Substitution and Replacement
With the help of the “re.sub()” method, you can easily replace matched patterns with the desired text. This is considered handy for updating or modifying strings or cleaning data.
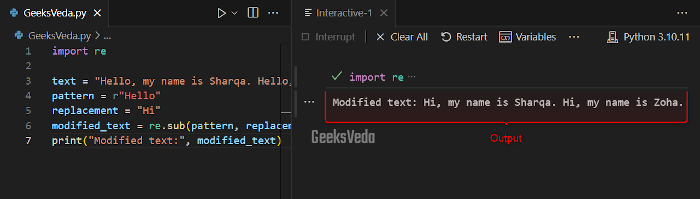
Now, let’s invoke the “re.sub()” method for replacing all occurrences of “Hello” with “Hi” in the given text.
import re
text = "Hello, my name is Sharqa. Hello, my name is Zoha."
pattern = r"Hello"
replacement = "Hi"
modified_text = re.sub(pattern, replacement, text)
print("Modified text:", modified_text)
Advanced Python Regex Techniques
This section will discuss the advanced Python regex techniques such as lookahead and look-behind assertions and flags for case-insensitive and multi-matching.
1. Lookahead and Lookbehind Assertions
Lookahead and lookbehind assertions can be utilized for expanding the functionalities of regular expressions in Python. They enable conditional matching based on the presence or absence of particular patterns before or after the defined positions.
These advanced techniques offer a way for asserting complex conditions without consuming characters in the text.
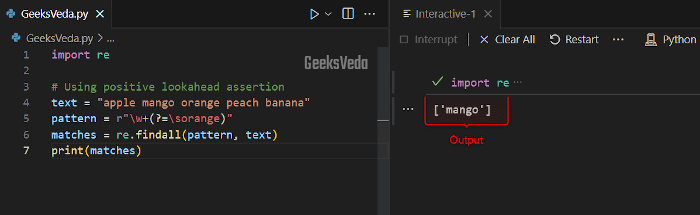
Here, in the provided code, the “?=\sorange” is the positive lookahead assertion. It makes sure that the specified match must be followed by a space and the word “orange“.
Moreover, the word “orange” will be excluded from the end result.
import re # Using positive lookahead assertion text = "apple mango orange peach banana" pattern = r"\w+(?=\sorange)" matches = re.findall(pattern, text) print(matches)
2. Flags for Case-Insensitive and Multiline Matching
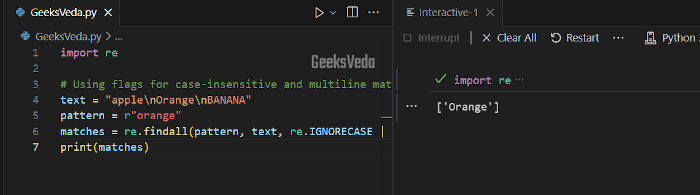
Python’s “re” module supports different flags that improve the flexibility of regular expression matching. Additionally, the “re.IGNORECASE” flag permits case-sensitive matching.
On the other hand, the “re.MULTILINE” flag enables you to match across multiple lines as follows.
import re # Using flags for case-insensitive and multiline matching text = "apple\nOrange\nBANANA" pattern = r"orange" matches = re.findall(pattern, text, re.IGNORECASE | re.MULTILINE) print(matches)
Regex Optimization in Python
With regex optimization, efficiency can easily meet precision. You can precompile patterns for faster processing and strike the balance between greedy and non-greedy matching.
1. Precompile Regex Patterns
Optimizing regex patterns with the help of precompilation can significantly improve the performance of the pattern-matching operations. Additionally, by the precompiling pattern with the “re.compile()” function, you can minimize the overhead of repeatedly compiling the same pattern.
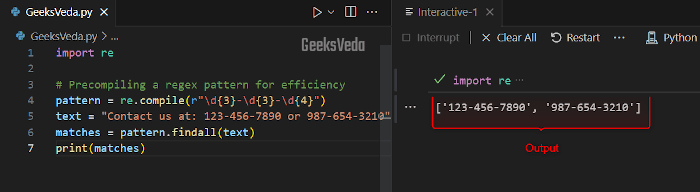
For instance, in the below code, we have added a regex pattern for phone numbers that will be precompiled with the “re.compile()” method.
This resultantly improves efficiency when performing multiple searches.
import re
# Precompiling a regex pattern for efficiency
pattern = re.compile(r"\d{3}-\d{3}-\d{4}")
text = "Contact us at: 123-456-7890 or 987-654-3210"
matches = pattern.findall(text)
print(matches)
2. Efficiency and Greedy vs Non-Greedy Matching
Efficiency in regex matching is essential, specifically when dealing with large texts. More specifically, greedy and non-greedy quantifiers affect how the patterns are matched which consequently impacts the performance.
Greedy quantifiers try to match as much text as possible. On the other hand, the non-greedy quantifiers match the shortest possible text.
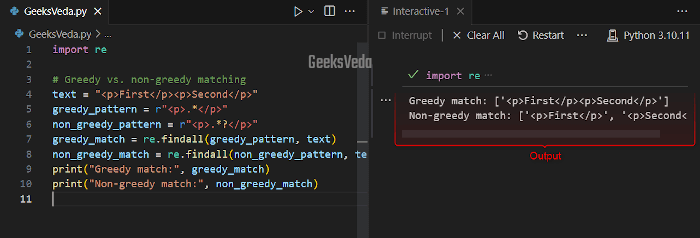
Here, the defined greedy pattern “r"<p>/*</p>” matches the whole content between the first “<p>” and the last “</p>“.
In contrast, the non-greedy pattern “r"<p>.*?</p>” match each individual “<p>” tag pair separately.
import re
# Greedy vs. non-greedy matching
text = "<p>First</p><p>Second</p>"
greedy_pattern = r"<p>.*</p>"
non_greedy_pattern = r"<p>.*?</p>"
greedy_match = re.findall(greedy_pattern, text)
non_greedy_match = re.findall(non_greedy_pattern, text)
print("Greedy match:", greedy_match)
print("Non-greedy match:", non_greedy_match)
For a head-to-head comparison between greedy and non-greedy quantifiers, check out the given table:
| Aspect | Greedy Matching | Non-Greedy (Lazy) Matching |
| Matching Behavior | Matches as much text as possible. | Matches as little text as needed. |
| Quantifier Syntax | Uses *, +, {}, and ? quantifiers. | Adds ? after quantifiers, e.g., *?, +?. |
| Example | .* matches the entire string, including multiple tags. | .*? matches the shortest possible content. |
| Performance | Can lead to performance issues with large input. | Typically more efficient for large input. |
| Use Case | Suitable for capturing broad patterns. | Ideal for extracting specific segments. |
| Specificity | Less specific, may include unintended content. | More specific, targets immediate content. |
| Application | Useful for finding patterns in multiline text. | Effective when content needs to be separated. |
Real-World Applications of Python Regex
Python regex can be used in real-world scenarios, such as for validating emails, URLs, and formats. You can also utilize them for extracting data through web scraping and text parsing. Its versatile capabilities enhance text manipulation for diverse applications.
1. Data Validation and Cleaning
Other than pattern matching, Python regex can be also applied in practical applications related to data validation and cleaning. Moreover, validating email addresses, URLs, and other formats can be simplified with regex patterns. This enhances the data integrity and accuracy.
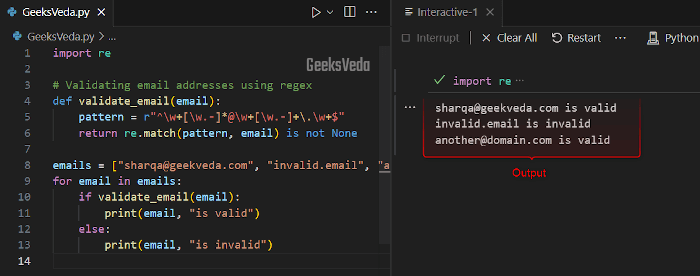
Here, the “validate_email()” function utilizes the specified pattern for validating the email addresses.
import re
# Validating email addresses using regex
def validate_email(email):
pattern = r"^\w+[\w.-]*@\w+[\w.-]+\.\w+$"
return re.match(pattern, email) is not None
emails = ["sharqa@geekveda.com", "invalid.email", "another@domain.com"]
for email in emails:
if validate_email(email):
print(email, "is valid")
else:
print(email, "is invalid")
2. Web Scraping and Text Parsing
Python regex also plays a crucial role in web scraping and text parsing. When information is required to be extracted from HTML, regex patterns assist in identifying and extracting relevant data points efficiently.
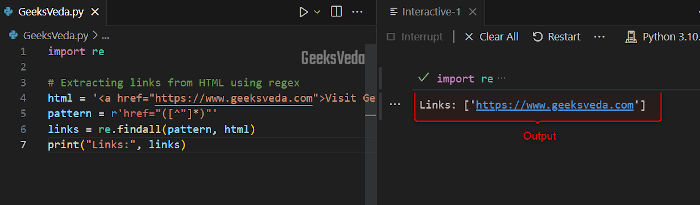
In the following example, we demonstrated how a regex pattern can be utilized for extracting or fetching URLs from HTML by matching the “href” attribute.
import re
# Extracting links from HTML using regex
html = '<a href="https://www.geeksveda.com">Visit GeeksVeda</a>'
pattern = r'href="([^"]*)"'
links = re.findall(pattern, html)
print("Links:", links)
That’s all from this informative guide related to Python regex and its usage.
Conclusion
Python regex permits you to perform different text-related operations. Additionally, with the help of the “re” module, you are allowed to match patterns, optimize data validation, and also streamline text parsing.
Therefore, in this guide, we have explained Python regex as a versatile toolkit for lookahead assertions, efficient precompilation, data validation and cleaning, web scraping, text parsing, and more.
Want to explore and learn more related to Python, do check out our dedicated Python Tutorial Series!