Are you ready for supercharging your Python application? In today’s guide, you will learn about the incredible world of Python threading and explore its potential for concurrent execution.
So, let’s discover its benefits, stages, and implementation in Python. Resultantly, you will be able to improve your coding skills and improve the efficiency of your application.
What is Threading in Python
In Python, threading refers to the process of achieving concurrency by permitting multiple threads of execution within a single process. More specifically, threads are lightweight and they share the same memory. This enables them to perform tasks simultaneously and run concurrently.
In Python, a thread is an independent flow of execution and there are two types of threads.
- Main Thread (automatically created).
- Additional Threads (manually created).
Stages of Thread in Python
Here, we have enlisted the stages of a thread in Python.
- New – When a thread has been created, however, not yet started.
- Runnable – When a thread is ready for execution and waiting for the scheduler to allocate processor time.
- Running – When a thread is actively running or executing the allocated tasks.
- Blocked – When a thread becomes temporarily inactive in case it is waiting for an event or resource.
- Terminated – When a thread completes its execution or is explicitly terminated.
Why Threading is Important in Python
Threading is considered important in Python for concurrent execution, better performance, and handling tasks simultaneously. It is useful in scenarios involving I/O operations, like file processing, and network communication, where waiting for these operations can be done concurrently, without blocking the main program’s execution.
Difference Between Threading and Multiprocessing
Beginners often get confused between the terms “Threading” and “Multiprocessing” and consider them the same. However, that’s not the case.
In order to know more about the main differences between threading and multiprocessing, have a look at the enlisted points.
- Threading involves executing multiple threads within a single process (sharing the same memory space), while Multiprocessing is based on running multiple processes, where each process has its own memory space.
- Threads share the same memory, which makes communication easier, however, they also introduce potential synchronization issues. On the other hand, processes have separate memory spaces, which make communication more complex but offer better isolation.
How is Threading Implemented in Python
For the implementation of threading in Python, utilizing the built-in “threading” module. Then, create a new thread by defining a method or function as the target.
Next, start the thread by invoking the “start()” method. Lastly, ensure the proper synchronization using locks and any other mechanism for safely sharing of resources.
Starting Thread
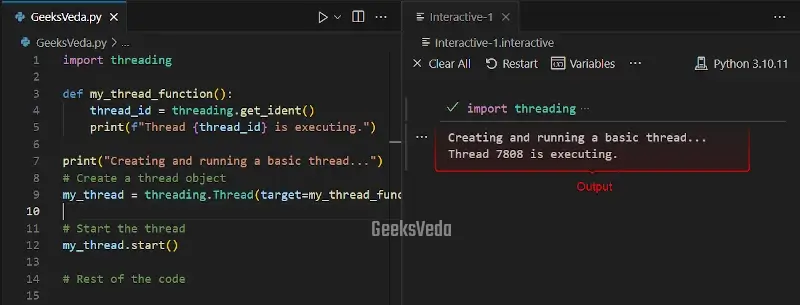
For instance, we will now first import the “threading” module and define “my_thread_function()” that is going to be executed by the thread. Next, we will create a “Thread” object and pass it to the target function to execute.
Then, start the thread by invoking the “start()” method. The target function will run in a separate thread and the thread ID will be displayed using the print() function.
import threading
def my_thread_function():
thread_id = threading.get_ident()
print(f"Thread {thread_id} is executing.")
print("Creating and running a basic thread...")
# Create a thread object
my_thread = threading.Thread(target=my_thread_function)
# Start the thread
my_thread.start()
# Rest of the code
Basic Synchronization Using Locks and Semaphores
Locks and semaphores are utilized for coordinating access to the shared resources in multi-threaded environments,
More specifically, locks offer exclusive access and permit only one thread to process. On the other hand, semaphores enable a specified number of threads for accessing a resource concurrently.
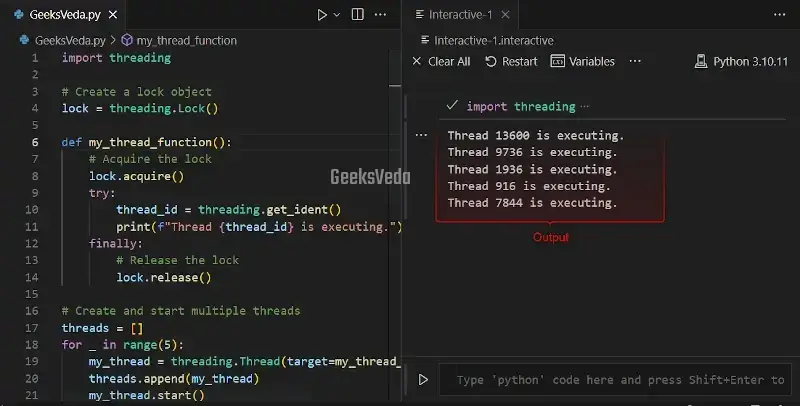
Here, we will use a lock object from the “threading” module for synchronizing access to a shared resource. This lock has been acquired with the help of the “acquire()” method before accessing the resource. Then, it is released with the “release()” method after verifying that the task is completed.
This makes sure that only one thread executed the code’s critical section at a time, which prevents concurrent access and potential conflicts.
import threading
# Create a lock object
lock = threading.Lock()
def my_thread_function():
# Acquire the lock
lock.acquire()
try:
thread_id = threading.get_ident()
print(f"Thread {thread_id} is executing.")
finally:
# Release the lock
lock.release()
# Create and start multiple threads
threads = []
for _ in range(5):
my_thread = threading.Thread(target=my_thread_function)
threads.append(my_thread)
my_thread.start()
# Wait for all threads to finish
for thread in threads:
thread.join()
# Rest of the code
Using Thread-local Data
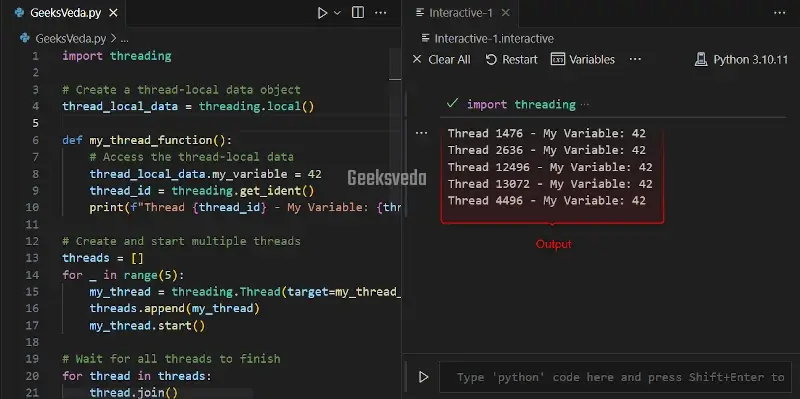
Thread-local data represent the variables that are unique to each thread and cannot be shared between multiple threads. It permits separate data instances to be maintained for each thread. This ensures thread-safe access and restricts interference between threads.
Now, we will use thread-local data by utilizing the “thread.local()” class. Note that each thread can have its own instance of “thread_local_data” and modifications to its attributes are isolated to the corresponding thread.
In the provided program, the value of the “my_variable” attribute of the thread-local data has been set to “42” and then accessed within the thread function.
Here, each thread displays its unique thread ID and the “my_variable” value, which demonstrates the data isolation between threads.
import threading
# Create a thread-local data object
thread_local_data = threading.local()
def my_thread_function():
# Access the thread-local data
thread_local_data.my_variable = 42
thread_id = threading.get_ident()
print(f"Thread {thread_id} - My Variable: {thread_local_data.my_variable}")
# Create and start multiple threads
threads = []
for _ in range(5):
my_thread = threading.Thread(target=my_thread_function)
threads.append(my_thread)
my_thread.start()
# Wait for all threads to finish
for thread in threads:
thread.join()
# Rest of the code
Thread Synchronization in Python
Thread synchronization is the process of controlling and building coordination between multiple threads for preventing data races and ensuring proper execution. It comprises approaches, such as locks, semaphores, and barriers for synchronizing access to the shared resources and maintaining thread safety.
Global Interpreter Lock (GIL)
Global Interpreter Lock or GIL is an essential mechanism in Python that enables only one thread to run Python bytecode at a time, even on multi-core systems. This signifies that Python threads cannot fully use multiple-core systems for CPU-bound tasks, by default.
However, the GIL doesn’t restrict threads from executing concurrently for I/O-bound tasks or tasks that release the GIL, such as certain C extensions.
Common Thread Synchronization Primitives
Python supports different thread synchronization primitives that are available for coordinating with the execution of the thread and ensuring thread safety. Some common primitives include locks, semaphores, conditions, and events.
Python Lock Object
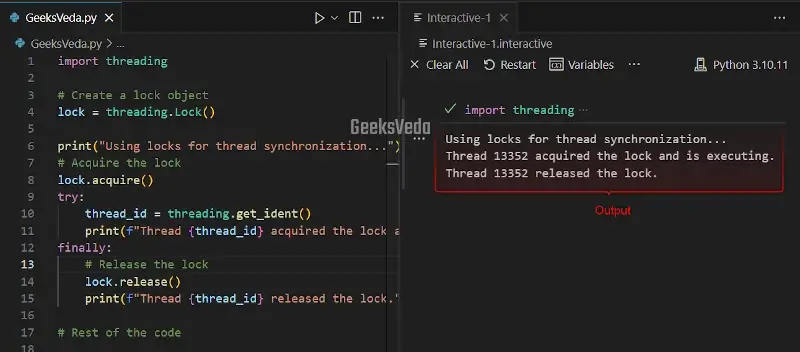
Now, we will create a lock object with the help of the “threading.Lock()“. The lock is then acquired using the “acquire()” method and released with the “release()” method.
The critical code section between acquiring and releasing the lock makes sure that only one thread runs at a time. This offers thread synchronization and restricts the data races.
import threading
# Create a lock object
lock = threading.Lock()
print("Using locks for thread synchronization...")
# Acquire the lock
lock.acquire()
try:
thread_id = threading.get_ident()
print(f"Thread {thread_id} acquired the lock and is executing.")
finally:
# Release the lock
lock.release()
print(f"Thread {thread_id} released the lock.")
# Rest of the code
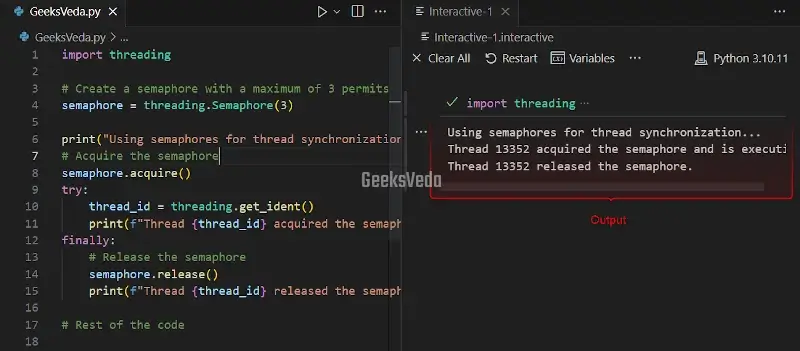
Threading Semaphore in Python
For instance, let’s create a semaphore with “threading.Semaphore(#)“, which permits a maximum of three threads for acquiring the semaphore simultaneously. The relevant semaphore is acquired by utilizing the “acquire()” method and releases with the “release()” method.
Threads that acquire the semaphore can process with the critical code section, while the other threads have to wait until the semaphore is released.
import threading
# Create a semaphore with a maximum of 3 permits
semaphore = threading.Semaphore(3)
print("Using semaphores for thread synchronization...")
# Acquire the semaphore
semaphore.acquire()
try:
thread_id = threading.get_ident()
print(f"Thread {thread_id} acquired the semaphore and is executing.")
finally:
# Release the semaphore
semaphore.release()
print(f"Thread {thread_id} released the semaphore.")
# Rest of the code
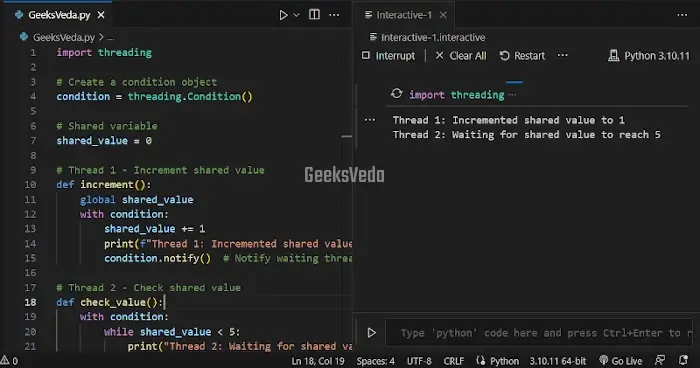
Threading Condition in Python
Now, we will utilize a condition object from the “threading.Condition()” for coordinating the execution of two threads. The “increment()” thread increments a shared value and sends a notification to the waiting thread by invoking the “condition.notify()“.
Then, the “check_value()” thread waits until the thread value reaches “5” using the “condition.wait()” method. This permits synchronized communication and coordination between the threads.
import threading
# Create a condition object
condition = threading.Condition()
# Shared variable
shared_value = 0
# Thread 1 - Increment shared value
def increment():
global shared_value
with condition:
shared_value += 1
print(f"Thread 1: Incremented shared value to {shared_value}")
condition.notify() # Notify waiting threads
# Thread 2 - Check shared value
def check_value():
with condition:
while shared_value < 5:
print("Thread 2: Waiting for shared value to reach 5")
condition.wait()
print("Thread 2: Shared value reached 5!")
# Create and start the threads
thread1 = threading.Thread(target=increment)
thread2 = threading.Thread(target=check_value)
thread1.start()
thread2.start()
# Wait for both threads to finish
thread1.join()
thread2.join()
print("All threads have finished execution.")
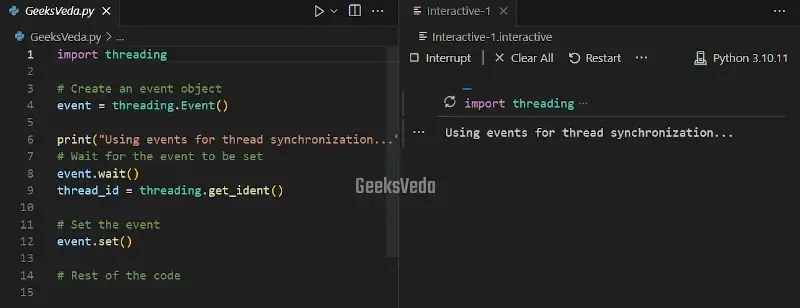
Threading Event Object In Python
According to the given program, we will now create an event object using the”threading.Event()“. The main thread then waits for the event to be set using the “event.wait()“, which blocks the execution until the event is set by another corresponding event.
More specifically, the event is set by utilizing the “event.set()” method, which enables the waiting thread to continue its execution.
import threading
# Create an event object
event = threading.Event()
print("Using events for thread synchronization...")
# Wait for the event to be set
event.wait()
thread_id = threading.get_ident()
# Set the event
event.set()
# Rest of the code
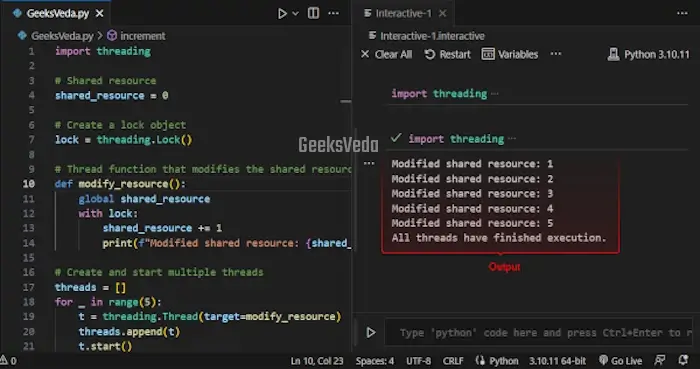
Implementing Thread Synchronization in Python
To implement thread synchronization, we will now create multiple threads where each thread modifies a shared resource which is a shared variable in this case. The lock makes sure that only one thread can modify the shared resource at a time. This maintains the thread safety and prevents the race condition.
import threading
# Shared resource
shared_resource = 0
# Create a lock object
lock = threading.Lock()
# Thread function that modifies the shared resource
def modify_resource():
global shared_resource
with lock:
shared_resource += 1
print(f"Modified shared resource: {shared_resource}")
# Create and start multiple threads
threads = []
for _ in range(5):
t = threading.Thread(target=modify_resource)
threads.append(t)
t.start()
# Wait for all threads to finish
for t in threads:
t.join()
print("All threads have finished execution.")
Thread Communication and Coordination in Python
Thread communication and coordination are based on mechanisms that are utilized for exchanging data and synchronizing their execution. Approaches like sharing data, queues, and barriers can be used for facilitating communication and making sure that there exists proper coordination between threads.
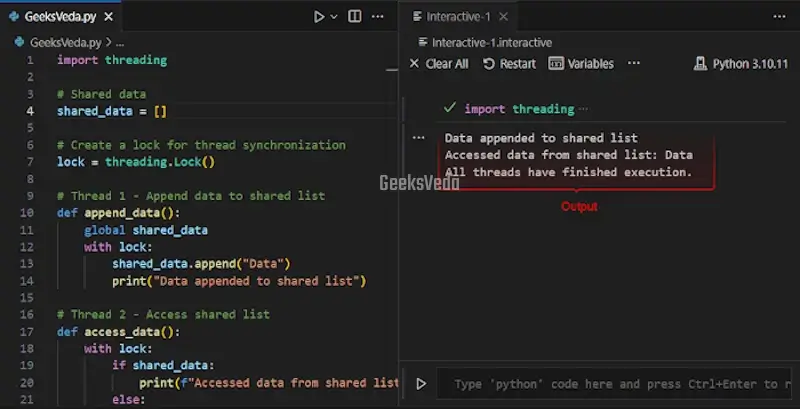
For instance, in the provided code, two threads are sharing a list named “shared_data“. The “append_data()” thread then appends “Data” to the list, while the “access_data()” thread accesses and displays the first element of the list.
More specifically, a lock has been utilized for synchronizing access to the shared data.
import threading
# Shared data
shared_data = []
# Create a lock for thread synchronization
lock = threading.Lock()
# Thread 1 - Append data to shared list
def append_data():
global shared_data
with lock:
shared_data.append("Data")
print("Data appended to shared list")
# Thread 2 - Access shared list
def access_data():
with lock:
if shared_data:
print(f"Accessed data from shared list: {shared_data[0]}")
else:
print("No data available in shared list")
# Create and start the threads
thread1 = threading.Thread(target=append_data)
thread2 = threading.Thread(target=access_data)
thread1.start()
thread2.start()
# Wait for both threads to finish
thread1.join()
thread2.join()
print("All threads have finished execution.")
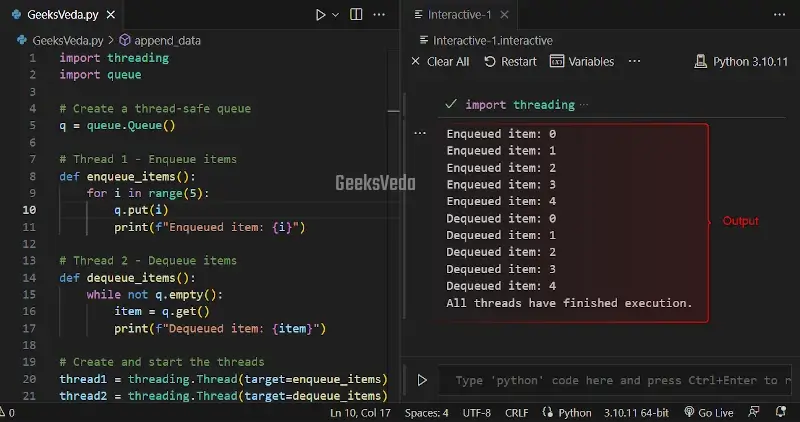
Using Queues for Thread-Safe Communication
A queue is a data structure that follows First-In-First-Out (FIFO) principle. It is utilized for holding a collection of elements where new elements have been added to the back and retrieval of elements starts from the front or top.
Here, a thread-safe “Queue” has been utilized for communication between threads. The “enqueue_items()” thread enqueues values into the queue. On the other hand, the “dequeue_items()” thread dequeues and displays the values.
import threading
import queue
# Create a thread-safe queue
q = queue.Queue()
# Thread 1 - Enqueue items
def enqueue_items():
for i in range(5):
q.put(i)
print(f"Enqueued item: {i}")
# Thread 2 - Dequeue items
def dequeue_items():
while not q.empty():
item = q.get()
print(f"Dequeued item: {item}")
# Create and start the threads
thread1 = threading.Thread(target=enqueue_items)
thread2 = threading.Thread(target=dequeue_items)
thread1.start()
thread2.start()
# Wait for both threads to finish
thread1.join()
thread2.join()
print("All threads have finished execution.")
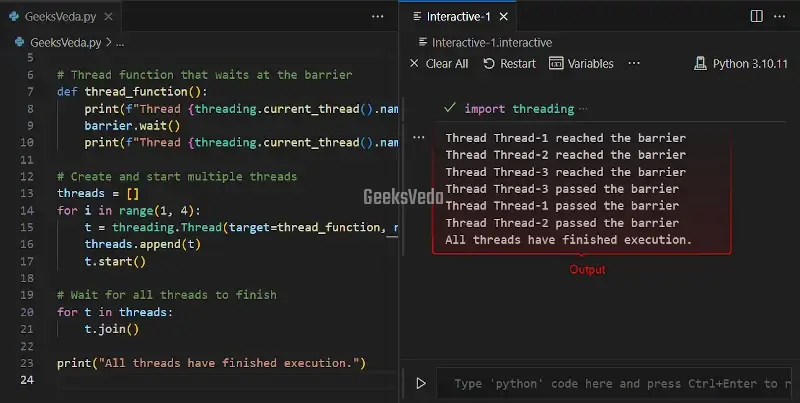
Coordinating Threads with Barriers
Barriers are commonly utilized for the execution of multiple threads. They make sure that certain conditions are met before proceeding with further computations.
For instance, here the multiple threads reach a barrier before continuing execution. Each thread shows a message when it reaches and passes the barrier.
import threading
# Create a barrier with a count of 3
barrier = threading.Barrier(3)
# Thread function that waits at the barrier
def thread_function():
print(f"Thread {threading.current_thread().name} reached the barrier")
barrier.wait()
print(f"Thread {threading.current_thread().name} passed the barrier")
# Create and start multiple threads
threads = []
for i in range(1, 4):
t = threading.Thread(target=thread_function, name=f"Thread-{i}")
threads.append(t)
t.start()
# Wait for all threads to finish
for t in threads:
t.join()
print("All threads have finished execution.")
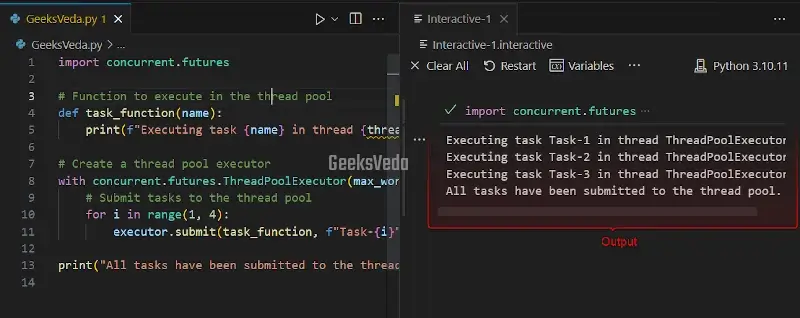
How to Implement Thread Pools in Python
Thread pools offer a convenient way of managing and reusing a fixed number of threads. They enhance performance by avoiding the overhead of creating and destroying threads for each task. Moreover, thread pools permit better control over the maximum number of concurrent threads.
For the implementation of thread pools, a “ThreadPoolExecutor” from the “concurrent.futures” module is utilized for creating a thread pool with a maximum of 3 worker threads.
Then, the tasks are submitted to the thread pool utilizing the “submit()” method. After that, the “task_function()” has been executed by the worker threads, and the results are automatically collected.
import concurrent.futures
# Function to execute in the thread pool
def task_function(name):
print(f"Executing task {name} in thread {threading.current_thread().name}")
# Create a thread pool executor
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
# Submit tasks to the thread pool
for i in range(1, 4):
executor.submit(task_function, f"Task-{i}")
print("All tasks have been submitted to the thread pool.")
Use Cases of Threading in Python
Threading can be proved beneficial in several scenarios such as web scraping and parallel file downloads. Let’s practically demonstrate each of them
Web Scraping
Web scraping refers to the process of retrieving data from websites automatically. It involves extracting web pages, parsing their content, and fetching the desired information. This technique saves time and effort compared to manual data extraction.
For instance, here multiple threads are utilized to concurrently scrape URLs using the “requests” library. Each URL is processed in a separate thread. This enables faster retrieval of the web data.
requests” library, first install it with this commandpip install requests
mport requests
import threading
# URLs to scrape
urls = [
'https://example.com/page1',
'https://example.com/page2',
'https://example.com/page3',
# Add more URLs here
]
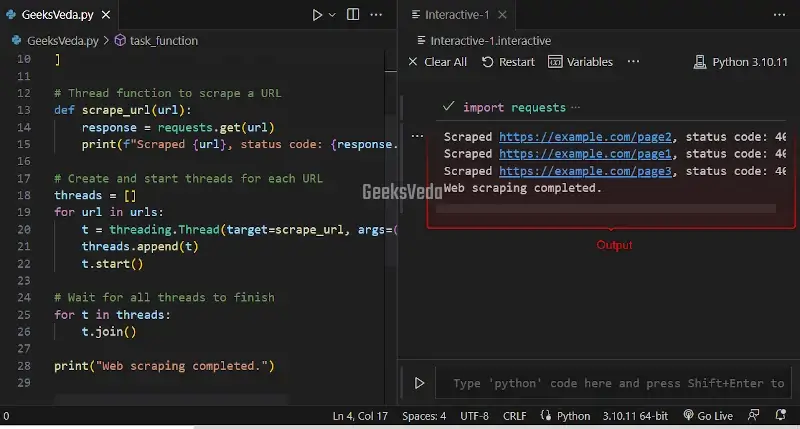
# Thread function to scrape a URL
def scrape_url(url):
response = requests.get(url)
print(f"Scraped {url}, status code: {response.status_code}")
# Create and start threads for each URL
threads = []
for url in urls:
t = threading.Thread(target=scrape_url, args=(url,))
threads.append(t)
t.start()
# Wait for all threads to finish
for t in threads:
t.join()
print("Web scraping completed.")
Download Multiple Files in Parallel
Now, let’s use multiple threads for downloading files from URLs with the help of the “requests” library. Observe that each file is downloaded concurrently in a separate thread, which enables faster downloads.
import requests
import threading
# URLs of files to download
urls = [
'https://example.com/file1.txt',
'https://example.com/file2.txt',
'https://example.com/file3.txt',
# Add more file URLs here
]
# Thread function to download a file
def download_file(url):
response = requests.get(url)
filename = url.split('/')[-1]
with open(filename, 'wb') as file:
file.write(response.content)
print(f"Downloaded {url} as {filename}")
# Create and start threads for each file download
threads = []
for url in urls:
t = threading.Thread(target=download_file, args=(url,))
threads.append(t)
t.start()
# Wait for all threads to finish
for t in threads:
t.join()
print("File downloads completed.")
Conclusion
Knowing about threading in Python is crucial for enhancing performance, achieving concurrent tasks, and efficiently handling multiple tasks simultaneously. It can also assist developers to optimize their Python applications for better responsiveness and efficiency.
Want to explore and learn more related to Python, do check out our dedicated Python Tutorial Series!